Как OpenEdge работает с блоками
Как происходит работа с блоками
Работа с блоками записей
Процесс добавления новой записи в базу данных очень важен — нужно соблюдать баланс между плотностью и фрагментацией данных. Высокий уровень компактности данных позволит считать за одну операцию ввода-вывода больше записей. Это увеличивает быстродействие. А если у вас много фрагментированных записей, то быстродействие уменьшается, так как чтение каждой фрагментированной записи требует чтения множества блоков.
Добавление новой записи в базу данных
Если в базу добавляется новая запись, то физическое размещение записи в базе выполняется по специальному алгоритму
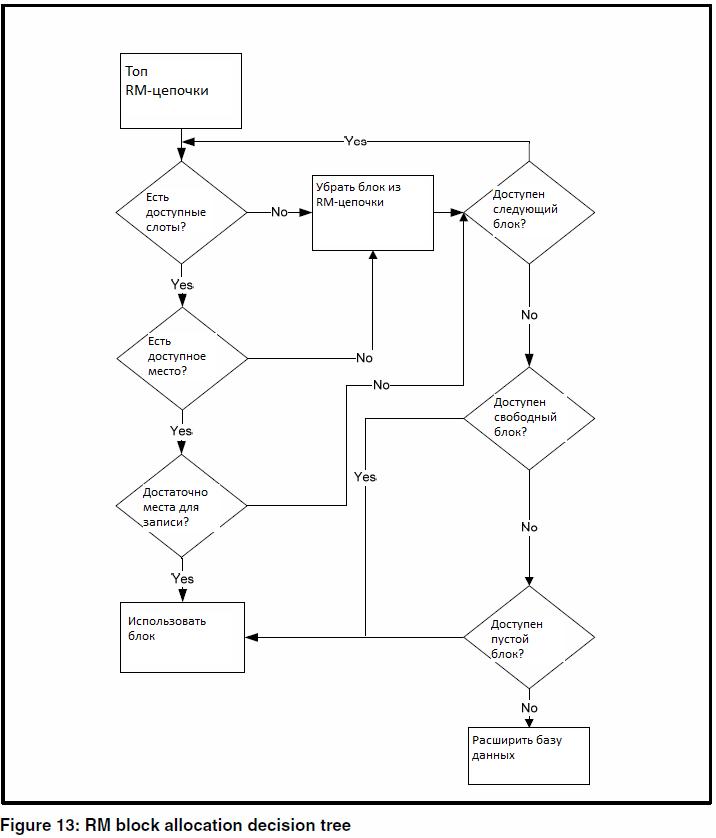
Добавлении новой записи в базу данных происходит по следующим правилам:
- Если блок не является блоком RM-цепочки или не входит в RM-цепочку, то происходит поиск следующего блока. Выполняется до 20 итераций.
- Если блок RM-цепочки полон или не содержит открытых слотов для размещения записи, то такой блок удаляется из RM-цепочки. Выполняется до 100 итераций.
- Если в блоке RM-цепочки есть доступное место, но его недостаточно для размещения записи, то такой блок помещается в хвост RM-цепочки. Выполняется переход к следующему блоку в цепочке. Всего возможно три итерации.
- Если в RM-цепочке нет блоков, то выделяется свободный блок.
- Если свободные блоки отсутствуют, выделяются несколько пустых блоков и обновляется значение HWM (High-Water Mark)
- Если пустые блоки отсутствуют, последний экстент области БД в которую мы добавляем запись — переменной длины и операционная система сообщает, что достаточно места — то база данных расширяет область хранения данных.
Обновление существующей записи
Процесс обновления существующей записи намного проще добавления новой. Помните, что при большом увеличении размера записи вы можете вызвать фрагментацию. Из-за фрагментации время последовательного сканирования записи может замедлиться в три-четыре раза . Фрагментацию записей можно минимизировать настройками.
Правила обновления записи:
- Если новая запись имеет такой же размер, как и оригинальная, то оригинальная запись заменяется обновленной
- Если новая запись меньше оригинальной, то оригинальная запись заменяется обновленной и информация о свободном месте в блоке корректируется
- Если новая запись больше оригинальной и в блоке есть свободное место для размещения новой записи, то оригинальная запись замещается обновленной, при этом используется свободное место блока
- Если новая запись больше оригинальной и в блоке нет свободного места для размещения дополнительной информации, то обновленная запись разделяется на два или более блока. Это называется фрагментированием записи.
Удаление записи
В движке БД OpenEdge реализованы эффективные алгоритмы для ресурсоемких операций. Операция удаления — одна из таких операций. Удаление записи откладывается до тех пор, пока не возникнет необходимость в повторном использовании места для хранения новой информации. Такой алгоритм устраняет ненужные операции ввода-вывода.
Правила удаления записи:
- Специальная запись-заполнитель замещает удаляемую запись. Это необходимо для поддержки отката транзакции
- Запись-заполнитель может быть удалена после фиксации транзакции
- Физическое удаление записи происходит позже по причинам оптимизации производительности
Работа с индексными блоками
Работать с индексными блоками лучше всего на высоком уровне. Они не так жестко структурированы, как блоки записей. Индексные блоки могут содержать в себе переменное число записей на блок, и знать это число совсем не нужно .
Индексная информация плотно упаковывается. Иногда возникает необходимость в дополнительном пространстве при добавлении элемента в середину индекса. Такой процесс называется разделением блока индекса (index block split). К примеру, у нас есть индексный блок, который содержит элементы 1, 2, 4 и 5 и в этом блоке больше нет свободного места. Нам необходимо вставить элемент 3. Эта операция требует разделения существующего блока на два, причем в этих блоках должно присутствовать по половине оригинального блока. В нашем примере разделения оригинальный блок будет содержать элементы 1 и 2, в то время, как новый блок (полученный из цепочки свободных блоков, из пустого блока или при расширении базы данных) будет содержть записи 4 и 5. Как только разделение завершено, элемент 3 добавится к оригинальному блоку. Блок 1, 2, 4, 5 разделится на два — 1, 2, 3 и 4, 5
Есть одна проблема, с которой вы встретитесь, когда индексы пройдут через значительное число блочных разделений, и называется она — фрагментация индексов. В этом случае необходима реорганизация индексов. Эта реорганизация может быть выполнена во время работы базы данных утилитой сжатия индексов . На скорость работы пользователей утилита практически не повлияет. Оффлайновая же утилита перестройки индексов удаляет все индексные элементы и перестраивает их заново. Это самый эффективный путь, но его минус состоит в том, что базу данных необходимо остановить на время перестройки индексов.
Самое важное, что нужно вынести из этой главы о блоках: надо помнить о том, что необходимо избегать фрагментации. Это возможно при грамотном создании базы данных и проектировании приложения (для записей), а также при использовании утилит (для индексов).
Знание основ внутреннего устройства базы данных OpenEdge не будет лишним. Обладая такими знаниями вы сможете принимать лучшие решения по созданию базы данных и по настройке вашей системы.